

On this page
- What is a semantic layer?
- A worked example: defining revenue once
- Semantic layer vs. the terms it gets confused with
- Why your AI agents need a semantic layer
- Governance and compliance: the semantic layer as the control point
- Where the semantic layer fits in the modern data stack
- The semantic layer landscape: which tools provide one
- How to build (or buy) a semantic layer
- Frequently asked questions
- The bottom line
Ask three people at your company what "revenue" means and you will get three answers. Finance counts recognized revenue. Sales counts bookings. The product dashboard counts something a former analyst defined two years ago and never wrote down. Each number is "right" in its own tool, and that is exactly the problem.
A semantic layer is how you fix it. It is one of those pieces of data infrastructure that sounds abstract until you realize it is the reason your dashboards disagree, your forecasts get re-argued in every meeting, and your new AI assistant keeps returning numbers nobody trusts.
What is a semantic layer?#
A semantic layer is a shared definition of your business metrics and entities that sits between your raw data and the tools that consume it. It translates how data is stored into how your business talks, so "revenue," "active customer," and "churn rate" mean the same thing everywhere.
Your data warehouse holds tables: orders, subscriptions, accounts, events. Useful, but no executive thinks in tables. They think in metrics. The semantic layer is where you define, exactly once, that "monthly recurring revenue" is this set of columns, with these joins, filtered this way. Then every dashboard, report, notebook, and AI agent reads that single definition instead of writing its own.
Think of it as the difference between a pile of ingredients and a recipe everyone agrees to cook from. The warehouse gives you the ingredients. The semantic layer is the recipe, and it makes sure the dish tastes the same no matter who is in the kitchen.
In one sentence: a semantic layer is the governed vocabulary of your business, defined once, on top of your warehouse, so every consumer of data computes the same metric the same way.
This idea isn't new. Business intelligence tools have had "semantic models" for decades: the layer in Looker, Power BI, or Tableau where you rename cust_id to "Customer" and define a few measures. What is new is pulling that layer out of any single BI tool and making it a standalone, governed foundation that everything else, including AI, can read. That shift is why the term is suddenly everywhere.
A worked example: defining revenue once#
Say you run a B2B SaaS company. You want one number: net revenue retention (NRR).
Without a semantic layer, here is how it goes. The finance analyst writes a query joining subscriptions to accounts, excludes trials, handles mid-month upgrades a particular way, and builds a dashboard. Three months later, a RevOps analyst needs the same metric for a board deck, doesn't know the first query exists, and writes their own, with a slightly different treatment of downgrades. Now you have two NRR numbers that are 4 points apart, and a meeting to figure out which one is "real."
With a semantic layer, NRR is defined once: the entities involved (accounts, subscriptions), the exact logic (starting recurring revenue, plus expansion, minus contraction and churn, over a cohort window), and the filters (exclude trials, exclude internal accounts). Every tool that asks for "net revenue retention," the board dashboard, the RevOps report, the AI agent in your CRM, gets that one definition. The number is the same because it is the same calculation, not a re-implementation.
That is the whole value in miniature: define the metric once, reuse it everywhere, and stop paying the tax of reconciling numbers that should never have differed. It is the operating principle behind a modern data strategy, the curated, governed "Gold" layer where business definitions live.
Semantic layer vs. the terms it gets confused with#
The semantic layer sits in a crowded vocabulary. Most of the confusion clears up once you see how it relates to each neighbor. Here is the short version, then a bit more on each.
| Concept | What it is | Relationship to the semantic layer |
|---|---|---|
| Data model | How data is structured: tables, columns, keys, relationships | The foundation underneath. The semantic layer adds business meaning on top of it. |
| Metric layer | The definitions of measures (revenue, retention) and how to calculate them | A part of a semantic layer, focused on the numbers. |
| dbt (transform) | A tool that cleans and reshapes raw tables into tidy ones | Prepares the data the semantic layer serves. Complementary, not the same job. |
| OLAP cube | Pre-aggregated data along dimensions for fast slicing | An older way to reach the same goal; a semantic layer computes on demand instead of pre-building. |
| Headless BI | A semantic layer exposed via API to any front end | The same thing, named for its delivery model (definitions decoupled from any one tool). |
| Semantic model | The actual content of a semantic layer (the metrics, entities, rules) | What you build inside the semantic layer. |
Semantic layer vs. data model#
A data model describes how your data is organized: which tables exist, what columns they hold, how they relate. It answers "how is this data structured?" A semantic layer sits on top and answers "what does this data mean to the business?" The data model connects orders to customers. The semantic layer says "revenue is the sum of order.amount for non-refunded orders, and you can slice it by customer segment." You need the data model first; the semantic layer gives it business meaning.
Semantic layer vs. metric layer#
A metric layer (or metrics layer) is the part of a semantic layer focused on measures: the formulas for revenue, conversion rate, retention. A full semantic layer is broader. It covers those metrics plus the entities, dimensions, relationships, and access controls around them. If someone says "metric layer," they usually mean the same idea with the spotlight on the numbers.
Semantic layer vs. dbt#
This one trips people up because dbt has a semantic layer feature. The distinction: dbt prepares data by running the SQL that cleans, joins, and reshapes raw tables. A semantic layer defines and serves metrics on top of that prepared data, at query time, to whatever asks. They work together. The dbt semantic layer is dbt's way of adding the serving layer to its transform engine. Cube is a semantic layer that runs independently of how you transformed the data.
Semantic layer vs. OLAP cube#
An OLAP cube is an older approach to the same goal: pre-aggregate data along dimensions so slicing is fast. Cubes pre-compute and store the combinations. A modern semantic layer defines the metrics logically and computes on demand against the warehouse (often with caching), so you get the consistency of a cube without rebuilding it every time a definition changes.
Semantic layer vs. headless BI#
"Headless BI" is a semantic layer described by its delivery model. The idea: separate the metric definitions (the "body") from any particular dashboard tool (the "head"), and expose them through an API so any front end can consume them. A headless BI product is, in practice, a semantic layer you can plug into many tools.
If your takeaway is "these are mostly different framings of one idea, a governed and reusable definition of business metrics," that is exactly right. Vendors slice it differently. The underlying need is the same.
Why your AI agents need a semantic layer#
For years, the semantic layer was a quiet best practice: nice for dashboard consistency, easy to skip. AI agents changed that. It went from "good hygiene" to "the thing that decides whether your AI is trustworthy."
Here is why. When you connect an AI agent to your data and ask "what was net revenue retention in EMEA last quarter?", the agent has to turn that question into a query. If it is writing SQL against raw tables, it is guessing: which table holds subscriptions, how to define EMEA, whether to exclude trials, how to handle mid-quarter changes. Sometimes it guesses right. Sometimes it returns a confident, specific, wrong number, and you have no way to tell which. That is what people mean when they say AI "hallucinates" metrics. It isn't making up data. It is making up definitions.
A semantic layer removes the guessing. Instead of writing SQL, the agent picks from metrics that are already defined and certified. It asks for "net revenue retention," filtered to "region = EMEA," and the semantic layer returns the one correct calculation. The agent's job shrinks from "reinvent our business logic on the fly" to "pick the right metric by name." That is the difference between a demo that impresses in a sales call and a number your CFO will put in a board deck.
The blunt version: a semantic layer is what stops your dashboard and your AI agent from disagreeing. If they read the same definitions, they return the same answers. If they don't, you are back to reconciling numbers, except now one of the sources talks back in fluent English and sounds certain.
This is also why grounding matters more than model choice. A more capable model writes more convincing SQL against your raw tables, and more convincing wrong answers. Trust doesn't come from a smarter agent. It comes from giving the agent a governed layer to query. It is the same principle as getting your data ready for machine learning: the quality of the output is capped by the quality and consistency of the inputs.
Governance and compliance: the semantic layer as the control point#
Everything above is about getting the same number everywhere. The flip side is controlling who gets which number, and being able to prove how it was produced. That is governance, and it is the second reason the semantic layer matters more once an AI agent is in the picture.
The stakes are concrete. Gartner predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by "AI-ready data," and Gartner's own definition of AI-ready data includes data that is "actively governed." Ungoverned data is not a compliance footnote. It is one of the main reasons AI projects fail.
The logic is the same as before. Because the semantic layer sits between your warehouse and everything that reads it, it is the one place to enforce access and definitions once, instead of re-implementing them in every dashboard, notebook, and agent. Govern the definition once; govern the access once too. This is what people mean by data governance for AI: trustworthy, access-controlled inputs, applied at the layer the AI actually queries.
It matters more for an agent than for a dashboard because an agent is harder to predict. A dashboard shows a fixed set of numbers to a known audience. An agent answers open-ended questions for whoever is chatting with it. If the rules live in the agent, you are one clever prompt away from a leak. If the rules live in the layer the agent has to query, they hold no matter what it is asked.
Access control an agent can't talk its way around#
You define access rules once, on the metrics and dimensions themselves: this role sees revenue but not broken out by individual rep; that region can only query its own accounts. Row-level and column-level security live in the semantic layer, so an AI agent inherits exactly the permissions of the person using it. It cannot return data the user is not allowed to see, because the restriction is enforced below the agent, not requested politely above it.
Masking what should never leave#
Sensitive fields, email addresses, card numbers, anything personally identifiable, can be masked or excluded at the layer, so PII never reaches a dashboard cell or an agent's context window in the first place. The safest data is the data the agent never receives.
A number you can audit#
Because a semantic layer is defined as version-controlled code, every metric has a history: what the definition is, when it changed, and who approved it. When a regulator, an auditor, or your own CFO asks "where did this number come from?", you can trace it, this metric, these joins, these filters, this commit, instead of reverse-engineering a query someone wrote a year ago. That data lineage is also what makes an AI answer defensible: the agent did not invent the figure, it asked for a certified metric whose calculation you can show on demand.
Compliance builds on top of it#
A semantic layer does not make you GDPR, HIPAA, or SOC 2 compliant by itself; compliance is a program, not a feature. But consistent definitions, enforced access, masked PII, and auditable lineage are the substrate those frameworks are built on. It is far easier to satisfy "show that only authorized people can see this data, and prove how it is calculated" when the answer lives in one governed layer than when it is scattered across every tool that touches the data.
This is the distinction people miss between data governance and AI governance. AI governance is about model behavior, bias, and oversight, the territory of frameworks like the EU AI Act. Data governance is about trustworthy, access-controlled inputs, and that is the semantic layer's job. You cannot govern the AI on top of data you have not governed underneath.
Where the semantic layer fits in the modern data stack#
A semantic layer doesn't stand alone. It is one link in a chain that runs from raw data to the agent asking a question:
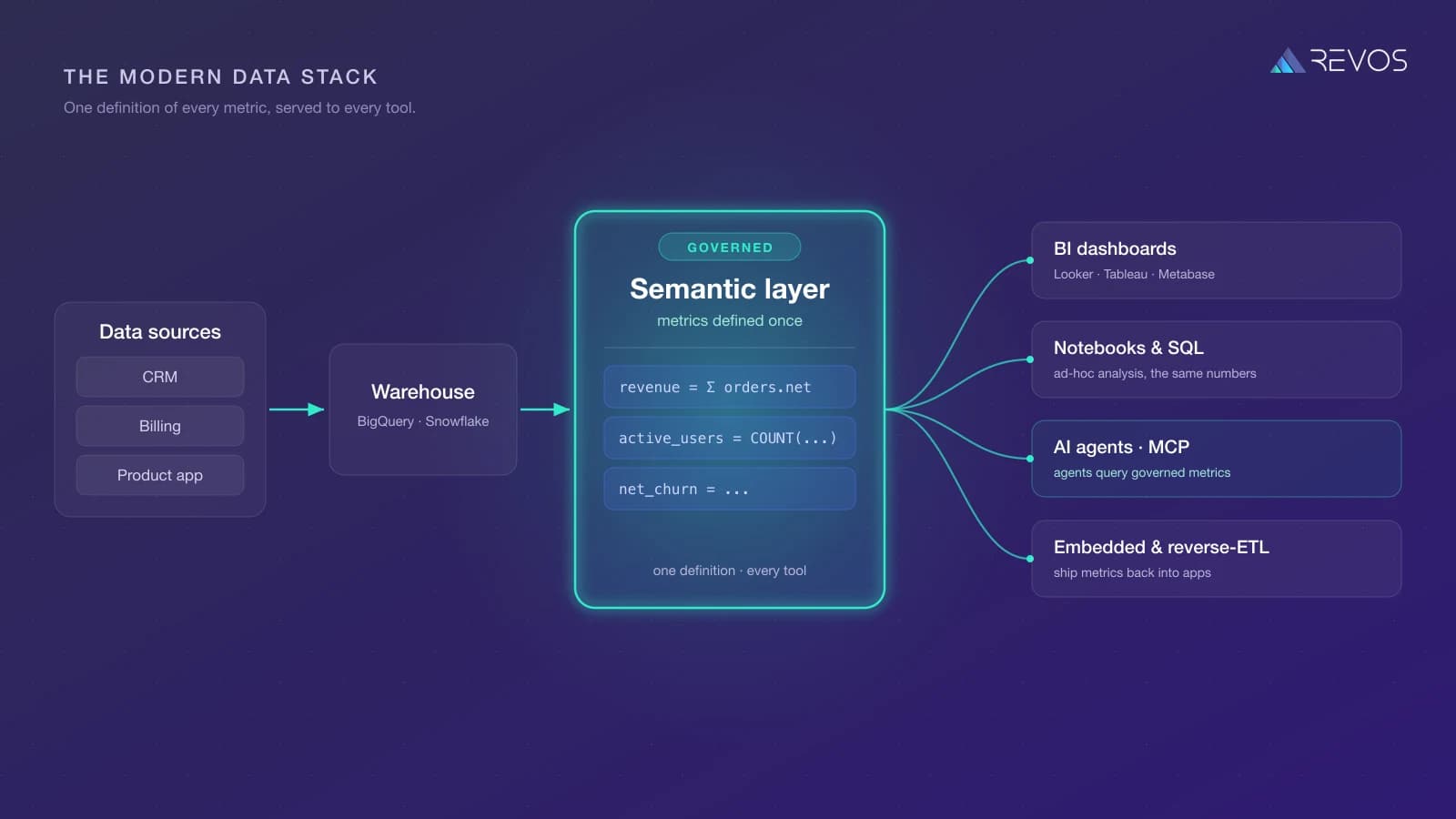
The chain has four stages, joined by the pipework that moves data between them:
- Your apps (CRM, billing, product) produce the raw data. Ingestion is what loads and syncs that data out of them and into the warehouse.
- The warehouse (BigQuery, Snowflake) stores and processes it.
- The semantic layer defines what the data means: the metrics and entities, defined once.
- Consumption is whatever reads the result: dashboards, notebooks, and increasingly AI agents.
The catch most teams hit: these steps are usually four or five separate products, each with its own contract, billing, and failure modes. You stitch ingestion to a warehouse to a transform tool to a semantic layer to a BI tool, and you spend more time maintaining the seams than using the data. The semantic layer is only as good as the warehouse it reads from and the consumption layer it feeds. A gap anywhere in the chain shows up as a wrong number at the end.
This is the case for bundling the stack rather than assembling it. When ingestion, warehouse, semantic layer, and consumption are one managed system, the metric you define flows cleanly from raw event to AI answer, with no integration tax and no drift between layers.
The semantic layer landscape: which tools provide one#
Once you decide you need a semantic layer, the question becomes which tool provides it. The options fall into a few groups, and the clearest way to tell them apart is where the layer lives.
| Tool | Type | What it is |
|---|---|---|
| Cube | Standalone / headless | Open-source semantic layer that serves any tool through an API. (RevOS runs on Cube.) |
| dbt Semantic Layer | Standalone, transform-attached | Metrics defined alongside your dbt transformations (MetricFlow). |
| AtScale | Standalone / headless | Enterprise semantic layer with an OLAP and BI-acceleration heritage. |
| Power BI / Microsoft Fabric "semantic model" | BI-tool–embedded | Microsoft renamed "dataset" to "semantic model" in 2023; the layer lives inside Power BI and serves Power BI reports. |
| Looker (LookML) | BI-tool–embedded | Google's modeling layer, written in LookML and tied to Looker. |
| Snowflake / Databricks | Warehouse-native | Metric and semantic definitions declared in the warehouse itself (Snowflake semantic views, Databricks metric views). |
| RevOS | Bundled platform | A Cube-powered semantic model bundled with ingestion, a managed BigQuery warehouse, and an MCP server for AI agents. |
The real dividing line is reach. Headless tools (Cube, dbt, AtScale) serve every downstream tool. BI-embedded models (Power BI, Looker) serve their own tool. Warehouse-native definitions tie the layer to one platform. RevOS bundles a headless, Cube-powered layer with the rest of the stack and exposes it over MCP, so the same certified metrics feed your dashboards and your AI agents.
How to build (or buy) a semantic layer#
If you build one yourself, the work splits into two parts, and the second is harder than the first.
The technical part: define your core entities (customers, accounts, subscriptions), your metrics with their exact calculations, the dimensions to slice by, and the access rules. The current best practice is to do this as version-controlled code on top of your warehouse, so definitions are reviewed, tested, and auditable like any other code. Cube is the leading open framework for this, which is why so many semantic layers (RevOS included) run on it under the hood.
The organizational part: getting people to agree on the single definition of each metric. This is where most efforts stall. The SQL is tractable. The meeting where finance and RevOps reconcile what "active customer" means is not. No tool skips that conversation, but the right setup makes it a one-time conversation instead of a recurring argument.
This is the gap RevOS is built to close. Two things make it different from assembling the stack yourself:
- An AI agent drafts the model. Instead of hand-writing every metric definition, you point RevOS at your data and an AI agent proposes the entities, metrics, and relationships, which your team reviews and refines. The first draft of the semantic model is generated, not typed from scratch.
- It is bundled, and it ships an MCP server. The semantic layer comes with the ingestion, the managed BigQuery warehouse, and the part no standalone semantic layer offers: a Model Context Protocol (MCP) server. That means any AI agent in Claude, Cursor, or your own application can connect and query your certified metrics by name, out of the box. The consumption layer for AI is built in, not a future integration project.
To be clear about the honest version: you do not need RevOS to have a semantic layer. dbt, Cube, and your BI tool can all get you one, and if you have the team to assemble and maintain the stack, that is a perfectly good path. What RevOS removes is the assembly, and it makes the AI consumption layer real from day one rather than something you wire up later.
Frequently asked questions#
What is a semantic layer in simple terms?#
A semantic layer is a translation between how your data is stored and how your business talks about it. Your warehouse has tables like orders, subscriptions, and accounts. Your team asks about revenue, churn, and active customers. The semantic layer defines those business terms once, including the exact tables, joins, and filters behind each one, so every dashboard, report, and AI agent uses the same definition instead of reinventing it.
What is the difference between a semantic layer and a data model?#
A data model describes how data is structured and related: tables, columns, keys, relationships. A semantic layer sits on top and adds business meaning: it defines metrics (revenue, MRR, churn rate), dimensions (region, plan, segment), and the rules for calculating them. The data model says how tables connect. The semantic layer says what a metric means and makes sure everyone computes it the same way.
What is the difference between a semantic layer and a metric layer?#
A metric layer (or metrics layer) is one part of a semantic layer. It defines measures like revenue, conversion rate, and net retention, and how to calculate them. A full semantic layer covers those metrics plus the entities, dimensions, relationships, and access rules around them. "Metric layer" emphasizes the numbers; "semantic layer" emphasizes the whole shared vocabulary.
What is the difference between a semantic layer and dbt?#
dbt is a transform tool: it runs the SQL that cleans, joins, and reshapes raw tables. A semantic layer defines and serves metrics on top of that prepared data, at query time. They are complementary. The dbt semantic layer is dbt's feature for adding that serving layer; Cube is a semantic layer that runs independently of how you transformed the data. The job is the same: one governed definition of each metric.
Is Snowflake a semantic layer?#
No. Snowflake is a data warehouse for storing and processing data. It can host or integrate a semantic layer, and it has added semantic features, but the warehouse itself stores tables, not business definitions. The semantic layer is a separate concern: the governed metric and entity definitions that sit above whatever warehouse you run on.
Is Databricks a semantic layer?#
No. Databricks is a lakehouse platform for storing and processing data. Like Snowflake, it can support a semantic layer and has added semantic capabilities, but the platform itself is not the semantic layer. The semantic layer is the set of governed metric and entity definitions on top of the platform.
What is a semantic layer in agentic AI?#
In agentic AI, the semantic layer is what an AI agent queries instead of writing raw SQL. The agent selects a certified metric by name, such as "net revenue retention," and the semantic layer returns the one correct calculation. This keeps the agent from guessing definitions and returning confident but wrong numbers. It is the grounding that makes an AI agent's answers trustworthy.
What is an example of a semantic layer?#
Take net revenue retention (NRR). In a semantic layer, NRR is defined once: the entities (accounts, subscriptions), the exact logic (starting recurring revenue, plus expansion, minus contraction and churn, over a cohort window), and the filters (exclude trials and internal accounts). Every tool that asks for NRR, including the board dashboard, the RevOps report, and an AI agent, gets that one definition and the same number.
How do you build a semantic layer?#
You define your core entities, your metrics with their exact calculations, the dimensions to slice them by, and the access rules, usually as version-controlled code on top of your warehouse, using a framework like Cube. The harder part is organizational: getting teams to agree on the single definition of each metric. RevOS shortens both by using an AI agent to draft the model from your data and bundling the semantic layer with the rest of the stack.
Does a semantic layer help with data governance and compliance?#
Yes. Because the semantic layer sits between your warehouse and every tool that reads it, it is where you enforce access rules and certified metric definitions once, instead of re-implementing them in each dashboard and AI agent. It does not make you GDPR, HIPAA, or SOC 2 compliant on its own, but consistent definitions, row- and column-level access control, PII masking, and version-controlled, auditable lineage are the foundation those compliance programs are built on.
How does a semantic layer control what an AI agent can access?#
You define access rules on the metrics and dimensions themselves, including row-level and column-level security, so an AI agent inherits the exact permissions of the person using it. The agent queries the semantic layer instead of raw tables, so it cannot return data the user is not allowed to see, and sensitive fields can be masked at the layer so personally identifiable information never reaches the agent's context.
What is the difference between data governance and AI governance?#
Data governance is about the inputs: making data accurate, access-controlled, private, and auditable. AI governance is about the model: its behavior, bias, explainability, and oversight. The semantic layer is a data governance tool, and it is the foundation AI governance depends on, because you cannot trust a model's output if you have not governed the data underneath it.
The bottom line#
A semantic layer is the shared, governed definition of what your business metrics mean. It is what makes a dashboard trustworthy, a metric reusable, and, now that AI agents are reading your data, an AI answer something you can act on.
For most of its history it was an optional nicety. The moment you put an AI agent in front of your data, it stops being optional. The agent is only as trustworthy as the definitions it queries. Give it raw tables and it will guess. Give it a semantic layer and it will give you the same answer your best analyst would: by name, on demand, every time.
If "ask your data and trust the answer" is where you are headed, the semantic layer is what gets you there. The only real question is whether you assemble it yourself or let it come bundled with the rest of the stack, ingestion to MCP, in one place.
Read more about revenue operations, growth strategies, and metrics in our blog and follow us on LinkedIn and Youtube.
All articles